最終更新日 2023年11月24日 by Quark Staff
Morphologicalは、形態素解析による辞書作成支援と、その辞書に従って頻度テーブルを作成する機能が含まれています。頻度テーブルは、機械学習に使うことを想定しています。日本語のみ対応です。
辞書作成支援
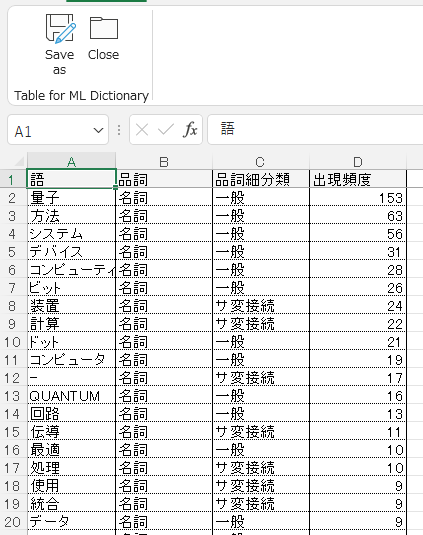
Dataシートにデータを展開し、Morphologicalを起動するとDictionaryタブが開きます。入力1に形態素解析にかけたい列を指定します。抽出したい品詞にチェックを入れRunします(多くのケースはデフォルト設定のまま実行して問題ありません)。
注意)複合名詞を含めると、抽出されるワードのバリエーションが増えるので注意してください。例えば、複合名詞ありで実行し、複合名詞である「量子コンピュータ」を抽出したとします。この場合、「量子」と「コンピュータ」はカウントされません。量子とコンピュータが、それぞれ独立して存在する場合にのみカウントされます。一般に、複合名詞をテキスト分析に含めると結果が複雑になりますので、特に必要ない限り、含めないことをおすすめします。尚、「全て」を選択した場合、複合名詞ありとなります。
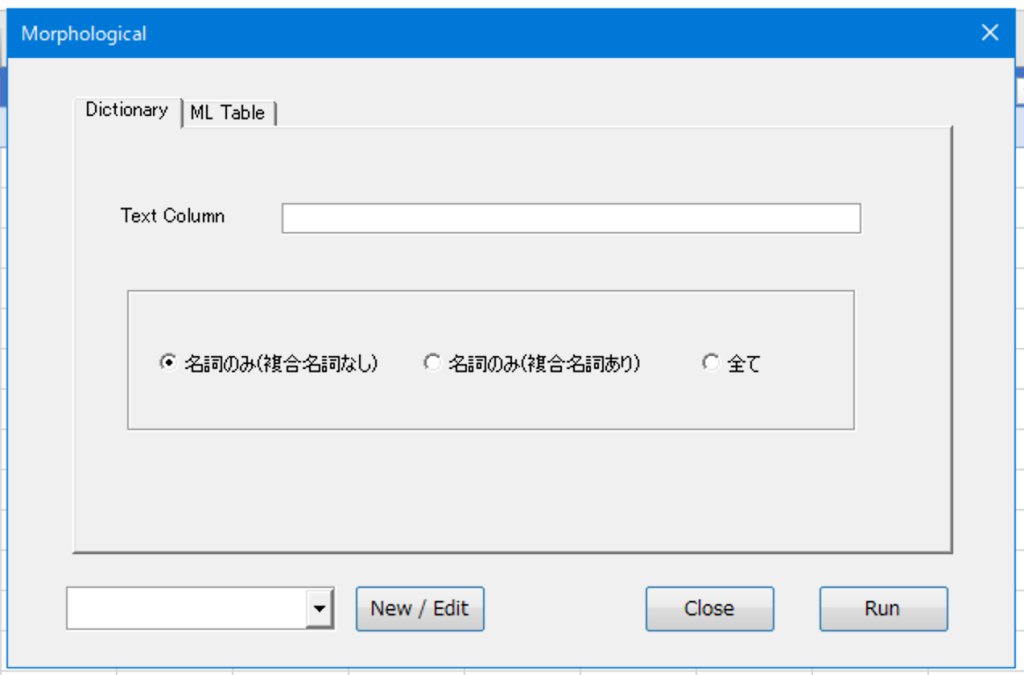
処理が終わると、抽出されたワードリストが開きます。不要なワード(あるいは出現頻度の少ないもの)があればここで削除し、ファイル名を入れて辞書として保存します。
ポイント)ここで取得した形態素解析結果は汎用性が高く、Text Mining (Japanese)やTag等、他のテキスト分析機能の辞書としても有用ですので、ペーストしてご利用ください。
頻度テーブル出力
データを展開し、Morphologicalを起動、Cross Tableタブに切り替えてください。入力1に分析したい列(頻度テーブルにしたいテキスト情報を含む列)を指定、入力2に目的変数が入った列を指定、また、左下のリストから集計に使う辞書(予めDictionaryで作成しておいた辞書)を指定しRunします。
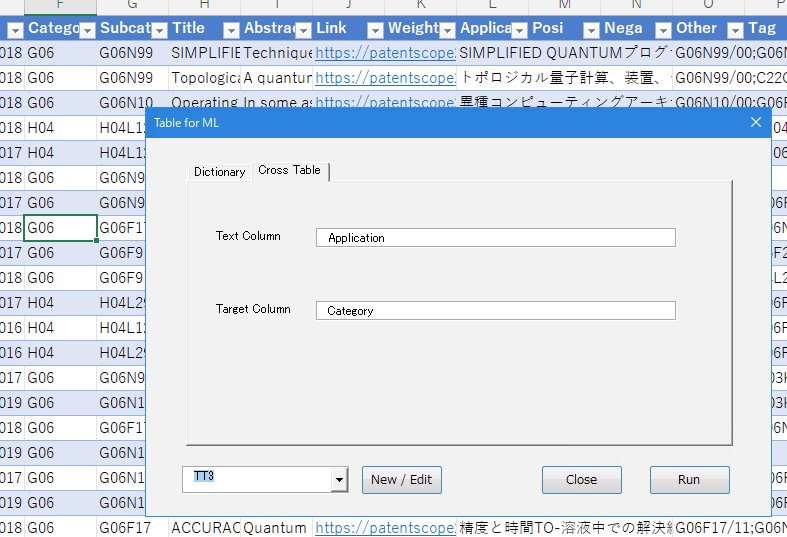
処理が終わると、各レコードにおけるワードの頻度が、以下のように集計され、Previewシートに展開されます。
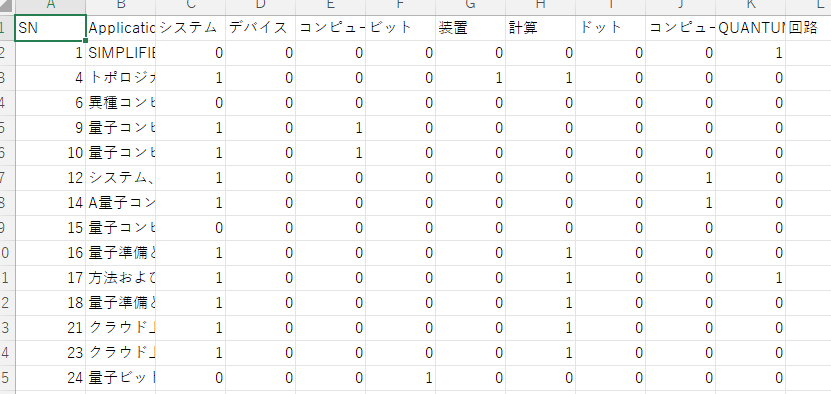
指定した目的変数は、テーブルの右端に追加されています。Previewシートに展開された状態ですので、Random ForestやClusteringをそのまま実行できます。教師あり学習や教師なし学習により、大量文書の分類やタグ付けが可能になります。