最終更新日 2024年5月1日 by Quark Staff
1つの文章を解析する機能ですが、一括ラベリングの前段階で、辞書作成を支援するような使い方を想定しています。
処理の実行
Sentence Analysisは、1つの文章を対象に分析する機能です。文章をペーストし処理すると、固有表現抽出、形態素解析、係り受け分析が分かりやすく視覚化されます。
Named Entitiesは固有表現抽出です。Data Labelingでは、この処理を一括で行っています。
辞書の登録
右のようなCSVファイルを用意し、左サイドバーのpatterns csvへドロップすると、結果が反映されます。なお、USER labelを指定すると、赤いハッチングが適用されます。右の例では、不確実、懸念、問題、などです。
この辞書は、そのままData Labelingでも使用できます。
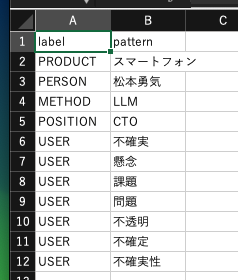
上記の例では、辞書を適用すると以下のように改善します。
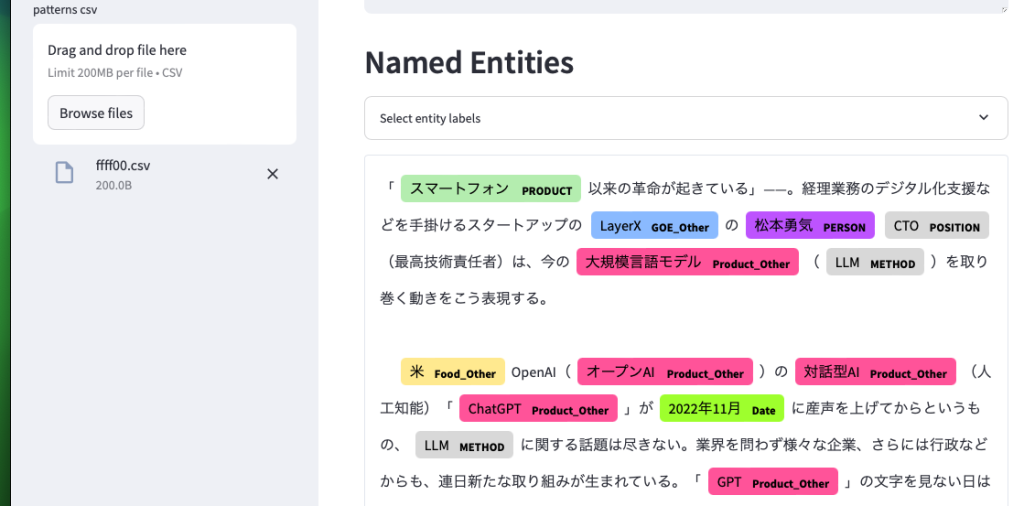
その他の解析
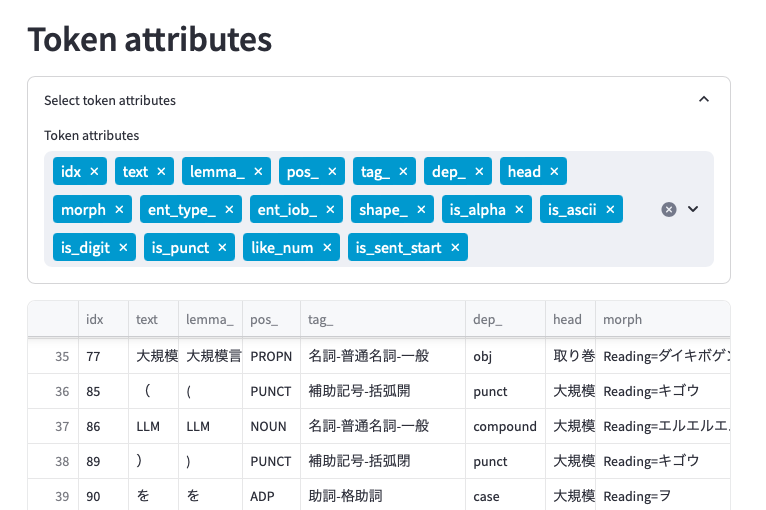
Token attributesでは、文章解析の結果を細かく見ることができます。品詞や係り受け情報も含め、CSVファイルでダウンロードできます。見落としていたワードや知見を発見し、辞書作成に役立てます。
Dependency Parse &・・では、文単位で係り受け関係が視覚化されています。
