最終更新日 2023年11月24日 by Quark Staff
Text Mining (Japanese)は、対象列(日本語)に対し形態素解析を行い、抽出したワードを各レコードに貼り付けます。
Mainタブ
入力欄に分析対象列を指定します。辞書を選択し、Runで実行します。
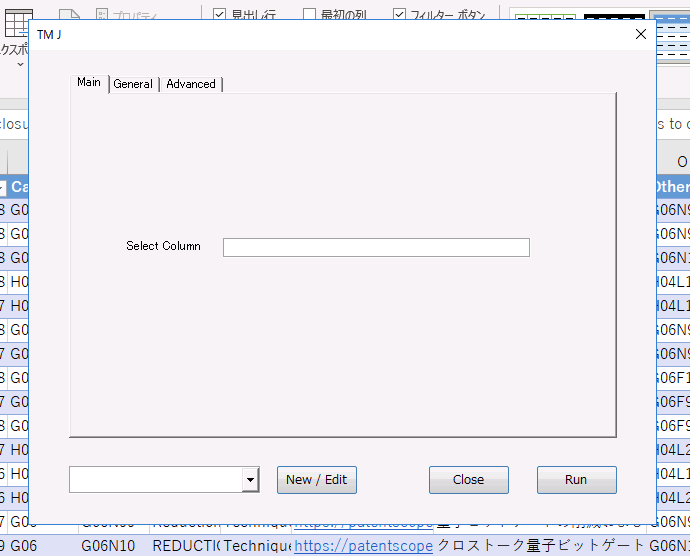
New/Editボタンで辞書を登録します。辞書では、Keyword、Stopword、Synonym(同義語)を登録します。ワードによってはStopwordが効かないケースがありますが、その場合は、Keywordにも同じワードを登録してください。
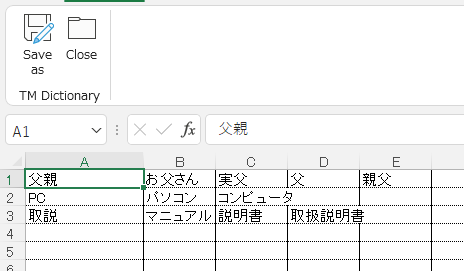
Synonymの登録は、以下のように登録してください。以下の例では、「お父さん、実父、父、親父」があったら、全て「父親」に置き換えて処理する、という意味です。
Save asで保存すると、ボタン左のリストに登録されます。
ポイント)テキスト分析の精度を上げるには、Keywordシートに、できるだけ多くのワードを登録して下さい。ワードの選定には、Morphlogical機能をお使い下さい。
Generalタブ
多くのケースは、デフォルト設定で問題ありません。必要に応じ、品詞または品詞細分類のチェックを見直してください。
重要)品詞カテゴリは形態素解析の計算に影響しますが、品詞再分類カテゴリは表示/非表示のみで、計算に影響しませんのでご注意ください。不要語を削除したい場合、この品詞再分類は最終手段とし、原則的には、辞書の登録でコントロールして下さい。
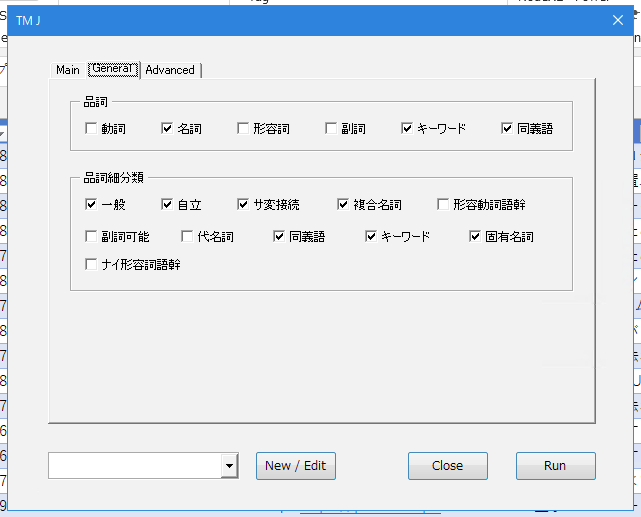
Advancedタブ
多くのケースは、空白で問題ありません。
出現頻度/出現件数の最小値は、例えば3を入力すると、2回以下の出現ワードは除外されます。
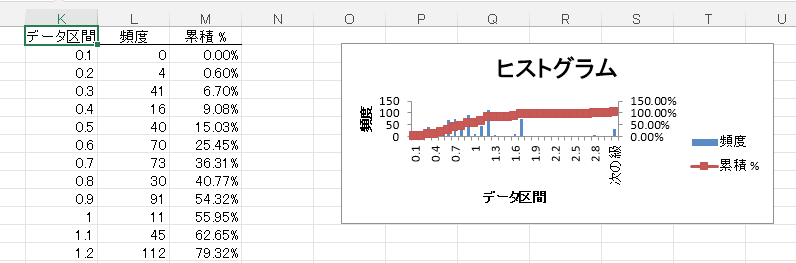
TFIDF閾値は、例えば3を入力すると、TFIDFが3以下のワードは除外されます。TFIDFの値は、Text Mining Jの出力ファイルに計算されています。ヒストグラム等を参照しながら、値を検討します。
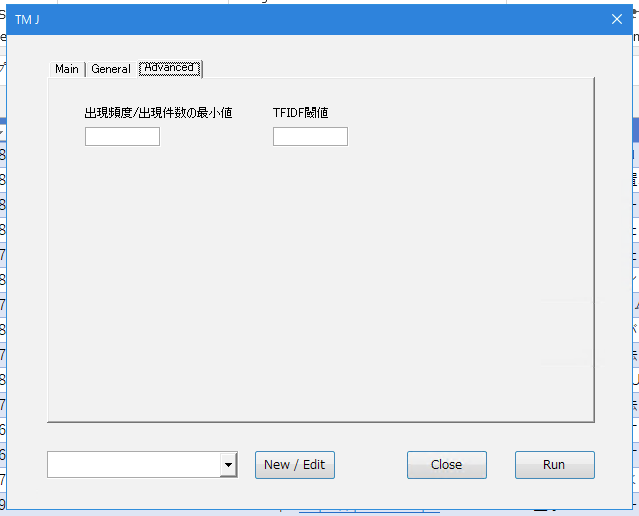
実行結果
出力列に、抽出ワードがカンマ区切りで貼り付けられます。TFIDF値が大きい順(重要度順)に貼り付けられています。俯瞰したい場合は、この列にTag Cloudを実行し確認してください。不要語などがあれば、辞書を見直して再度Text Miningを実行します。
出力ファイル
データ処理が終わるとSaveフォルダにファイルを出力します。出力ファイルは、抽出した全ワード、出現頻度や出現件数、TFIDF値やその分布といった情報の他、辞書登録機能も備えています。
【TM_Wordシート】
各レコードの文章から、どのようなワードが抽出されたかを確認できます。品詞やTFIDF値も確認できます。

【TM_ttm1シート】
抽出された全ワードが出現頻度順にリストされています。また、このシートでは、辞書の見直しができます。例えば、このシート上で何らかのフィルターをかけ、左上のいずれかのボタンを押すと辞書に一括登録されます。例えば、特定の品詞細分類だけを表示して、Stopwordのボタンを押すと、表示されているワードが一括してStopwordに登録されます。出力ファイルと辞書の紐付けは、TM_Infoシートに記載されています。
【TM_TFIDFシート】
TFIDF値の分布がヒストグラムで表示されています。重要度の低いワードを、どのくらいの値で足切りするかを検討してください。