最終更新日 2023年3月10日 by Quark Staff
Clusteringは、正解データを用意することなく、データを分類することができます。教師なし学習の一つです。
処理の実行
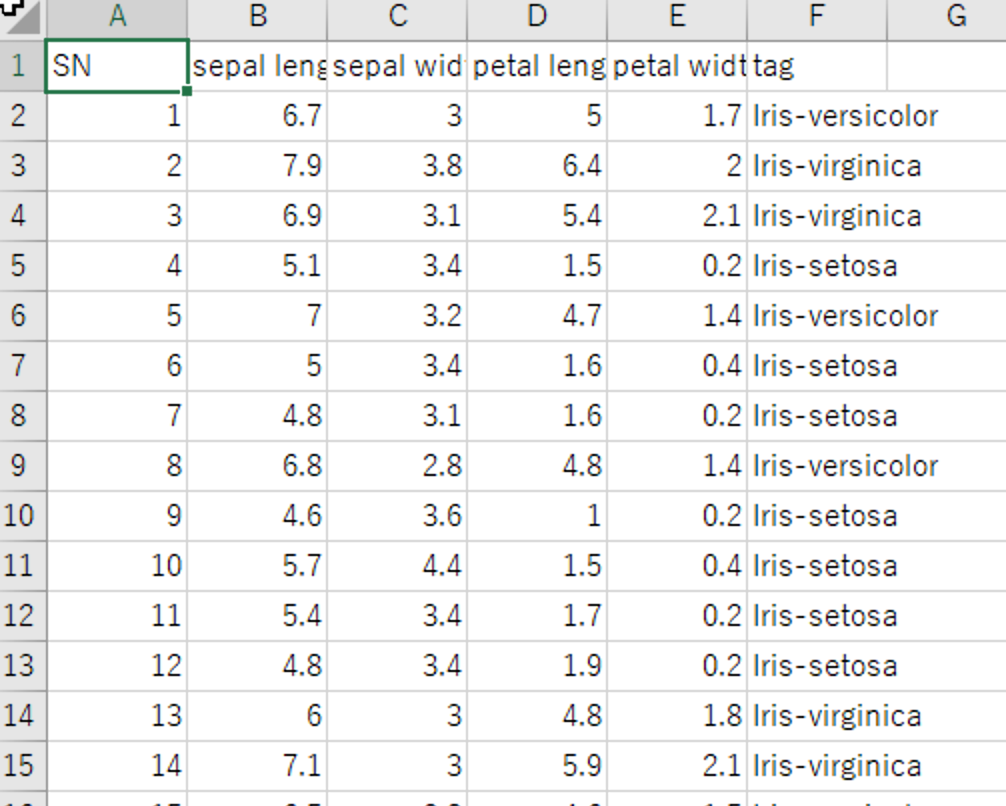
Dataシートにデータを展開します。量的データ(数値データ)は全て分析の対象になりますので、不要な列があれば削除してください。質的データは(下の例ではF列)、自動的に無視されますのでそのままで問題ありません。
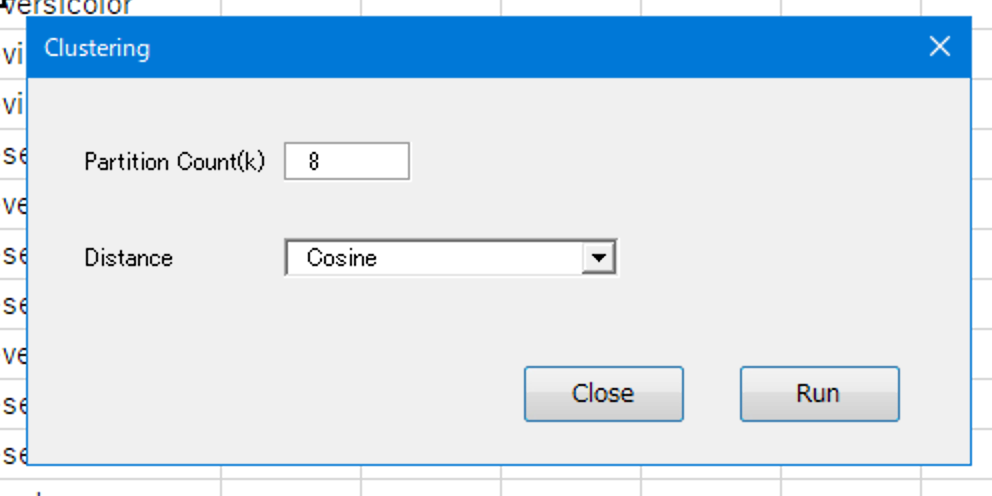
Clusteringを起動します。Partition Countでクラスタ数を指定します。Distanceで距離のアルゴリズムを指定し、Runで実行します。
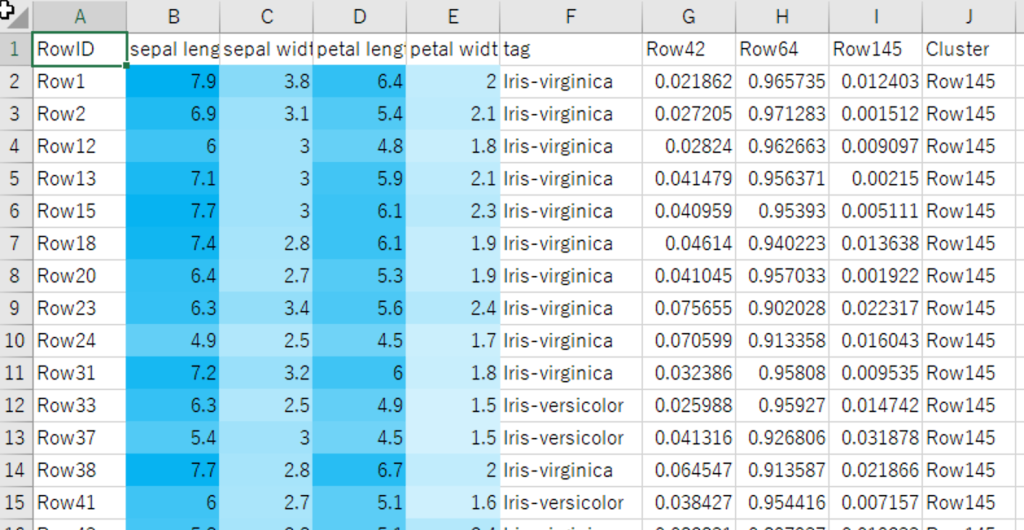
出力ファイル
出力ファイルのCluster列に(下の例ではJ列)、推定されたクラスタ番号が貼り付きます。予め正解データを質的データで残しておけば(下の例ではF列)、クラスタ分析の結果と比較することができます。