最終更新日 2023年3月10日 by Quark Staff
Random Forestは、予め正解データを用意して学習させ、そのモデルを使って分類や予測を行うものです。教師あり学習の一つです。
Contents
モデルの作成(学習)
Dataシートに、正解データをロードします。不要な説明変数(列)は、予め削除してください。質的変数、量的変数が混在していても問題ありません。
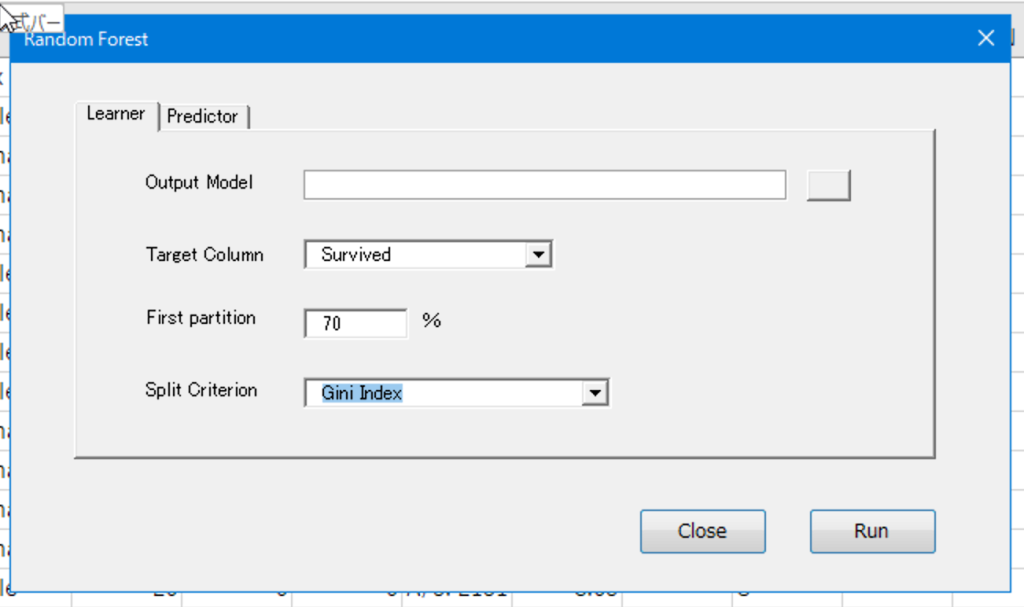
Random Forestを起動します。Output Modelにモデルの保存先とファイル名を指定します。Target Columnでは目的変数となる列を選択します。First Partitionではデータの何%を学習用に使うかを指定します。70%なら、データの70%を学習に使い、残り30%は予測の検証に使われます。Split Criterionでは分岐のアルゴリズムを選択します。
実行するとファイルが出力されます。出力ファイルのPrediction outputシートが残り30%の予測結果です。また、Accuracy statisticsシートでは予測の精度が確認できます。下の例では、このモデルが約81%(Accuracy列)の精度であることがわかります。精度が悪い場合は、最初に戻って説明変数を見直すか、正解データの数やアルゴリズムを再検討してください。

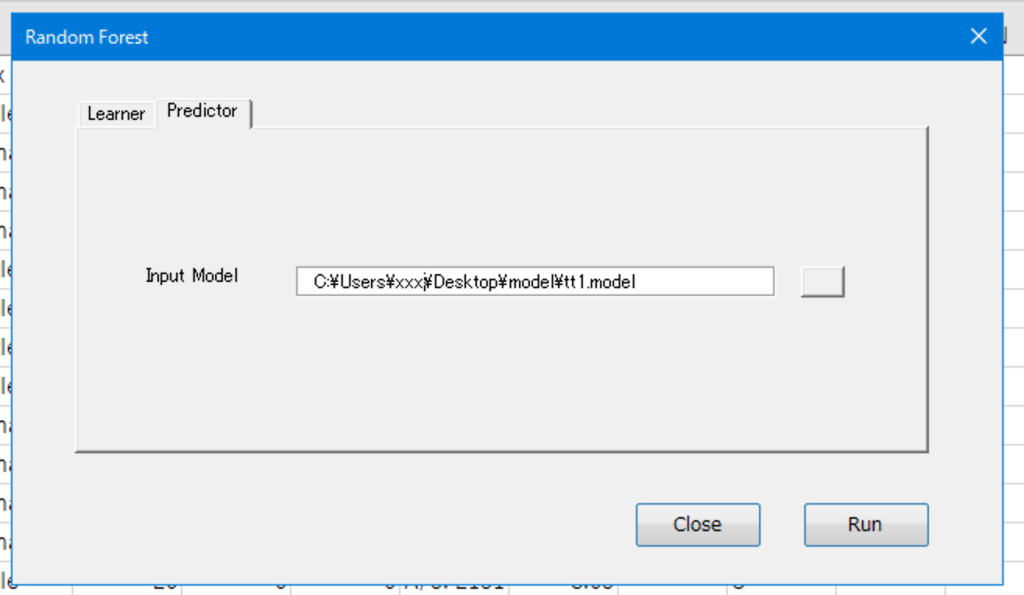
モデルの適用(予測)
Dataシートに、予測したいデータをロードします。モデルで使用した説明変数が全て含まれている必要があります。不要な列は無視されるので残っていても問題ありません。
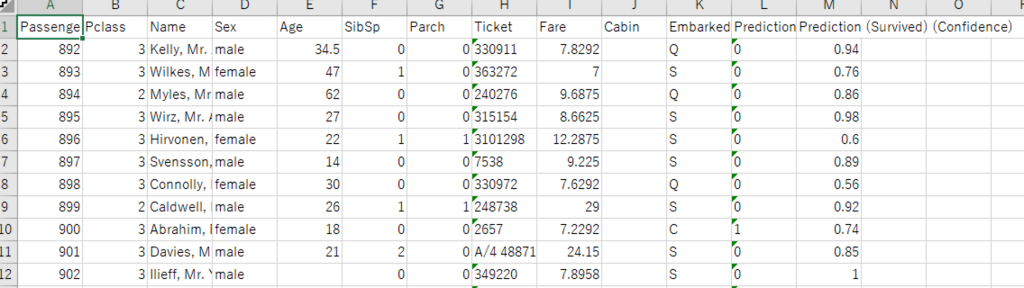
Random Forestを起動し、先に作成したモデルを指定してRunします。
出力ファイルには、各レコードの予測値(Prediction)と予測の信頼性が付与されます。