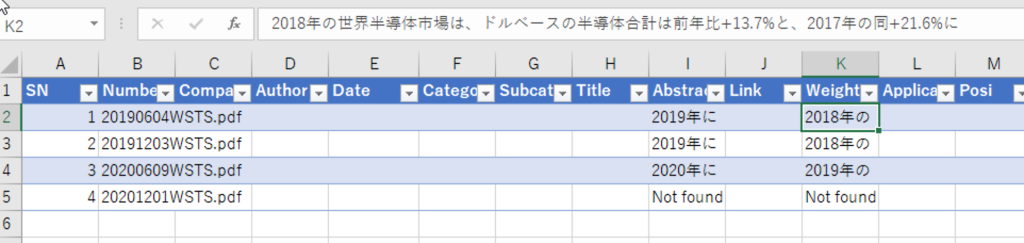
最終更新日 2023年11月24日 by Quark Staff
OCR Selected Regionは、Copy Full Textと同様に、PDFなどのオフィス文書を連続オープンし、テキスト情報を取得してExcelファイルにリスト化する自動プログラムです。その違いは、OCR Selected Regionは、必要な部分だけを取得できる点です。起点となる画像を登録し、その画像を手がかりに、近くの文字情報をOCRで取得します。単純コピーと比べ、文字化けや誤認識が起こる点がデメリットです。誤認識を少しでも軽減するよう、PDFリーダーのデフォルト値を全画面表示、拡大率は幅に合わせる設定をおすすめします。
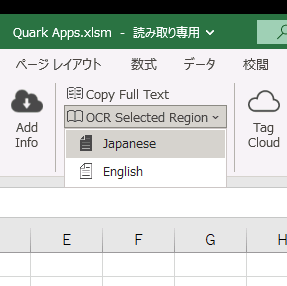
OCR Selected Regionを起動します。日本語OCRか英語OCRを選んで下さい。
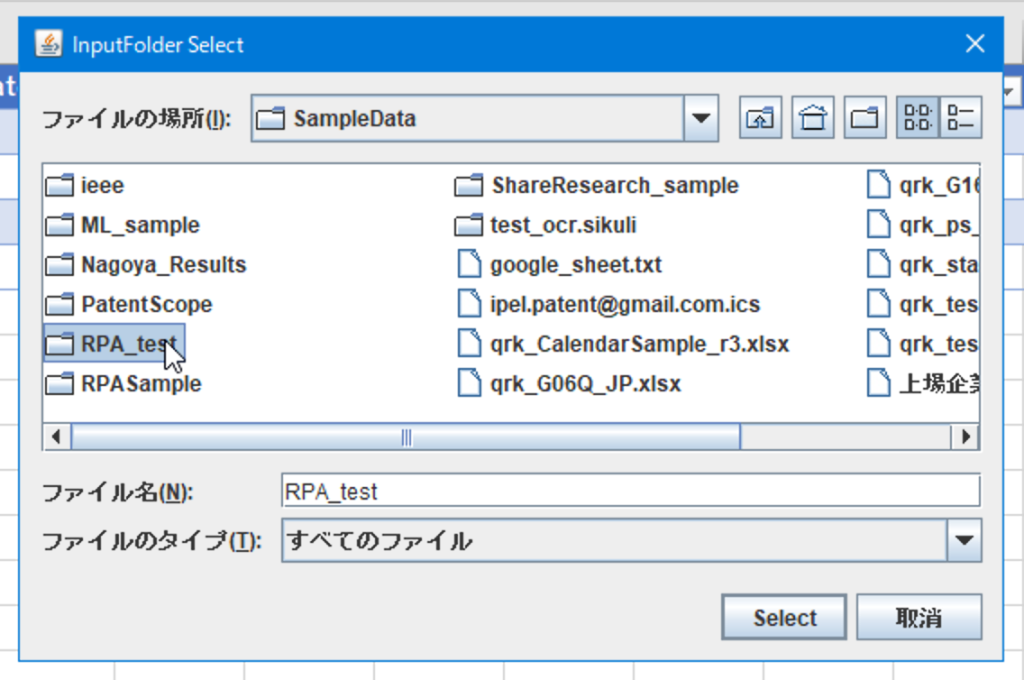
RPAが起動し、文書が保存されているフォルダを指定します。フォルダ内にあるすべてのファイルが対象になりますので、予め不要なファイルは移動しておいてください。Selectを押すと処理がはじまります。
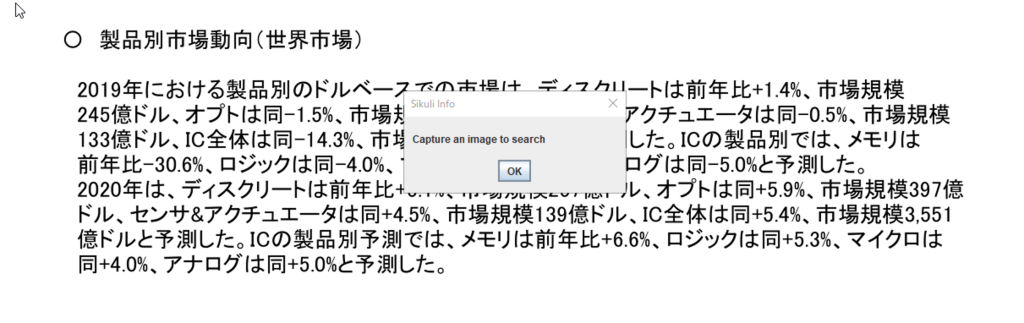
Capture an image to searchが表示されたら、起点となる画像があるページまでスクロールします。起点画像が表示されたらokを押します。
capture an imageが表示されますので、起点となる画像を指定します。左上から右下へ領域指定してください。起点画像は、特徴的でばらつきが少なく、鮮明な画像を登録してください。

次にSelect regionが表示されますので、OCRする領域を指定します。左上から右下へ領域指定してください。ここで、起点画像との相対位置が登録されます。すべてのファイルで、希望する情報が取得できるように、余裕を持って領域指定してください。後で変更できません。

OCRする領域を指定すると、すぐに処理がスタートします。PCから手を離してください。起点画像のサーチ中は自動でスクロールしますが、しばしば見落としがあります。最終ページまでサーチし数分経過した後、次のファイルへ処理が移ります。取得できなかった場合は、Not foundと記録されます。